Singlestep

一用IDA打开发现就弹出来一堆报错
看汇编发现IDA把很多代码识别成数据了
然后猜测是SMC,在sub_13C0中使用mprotect来使.text段可写

但是找不到解密算法
动调发现解密就在那些数据块里面,执行时先xor恢复内容,执行完后又xor回去,导致无法直接动调到后面看具体代码。

既然IDA无法识别,那就直接写个脚本来识别吧
import struct
import json
from capstone import *
# 初始化 Capstone 反汇编器
md = Cs(CS_ARCH_X86, CS_MODE_64)
def parse_bytes(data_bytes, base_addr):
stream_dict = {}
sorted_stream = []
for i, b in enumerate(data_bytes):
addr = base_addr + i
stream_dict[addr] = b
sorted_stream.append((addr, b))
return stream_dict, sorted_stream
def decode_xor_instruction(sorted_stream, i):
n = len(sorted_stream)
addr = sorted_stream[i][0]
if i+3 < n and sorted_stream[i][1] == 0x66 and sorted_stream[i+1][1] == 0x81 and sorted_stream[i+2][1] == 0x35:
if i+3+6 <= n:
offset_bytes = bytes([sorted_stream[i+3+j][1] for j in range(4)])
offset_val = struct.unpack("<i", offset_bytes)[0]
imm_bytes = bytes([sorted_stream[i+7+j][1] for j in range(2)])
imm_val = struct.unpack("<H", imm_bytes)[0]
instr_len = 1 + 2 + 4 + 2 # 共 9 字节
return {
'instr_start': addr,
'instr_len': instr_len,
'type': 'word',
'offset': offset_val,
'imm': imm_val
}
elif i+2 < n and sorted_stream[i][1] == 0x81 and sorted_stream[i+1][1] == 0x35:
if i+2+6 <= n:
offset_bytes = bytes([sorted_stream[i+2+j][1] for j in range(4)])
offset_val = struct.unpack("<i", offset_bytes)[0]
imm_bytes = bytes([sorted_stream[i+6+j][1] for j in range(4)])
imm_val = struct.unpack("<I", imm_bytes)[0]
instr_len = 2 + 4 + 4
return {
'instr_start': addr,
'instr_len': instr_len,
'type': 'dword',
'offset': offset_val,
'imm': imm_val
}
elif i+2 < n and sorted_stream[i][1] == 0x80 and sorted_stream[i+1][1] == 0x35:
if i+2+5 <= n:
offset_bytes = bytes([sorted_stream[i+2+j][1] for j in range(4)])
offset_val = struct.unpack("<i", offset_bytes)[0]
imm_val = sorted_stream[i+6][1]
instr_len = 2 + 4 + 1
return {
'instr_start': addr,
'instr_len': instr_len,
'type': 'byte',
'offset': offset_val,
'imm': imm_val
}
return None
def extract_pushfq_group(sorted_stream):
groups = []
n = len(sorted_stream)
i = 0
while i < n:
addr, b = sorted_stream[i]
# pushfq (0x9C)
if b == 0x9C:
group = {'push_addr': addr, 'pop_addr': None, 'xor_list': []}
i += 1 # 跳过 pushfq
# 在本组内连续尝试解码 xor 指令,直到遇到 popfq (0x9D)
while i < n and sorted_stream[i][1] != 0x9D:
xor_info = decode_xor_instruction(sorted_stream, i)
if xor_info is not None:
instr_end = xor_info['instr_start'] + xor_info['instr_len']
effective_addr = instr_end + xor_info['offset']
xor_info['effective_addr'] = effective_addr
group['xor_list'].append(xor_info)
i += xor_info['instr_len']
else:
i += 1
# popfq (0x9D)
if i < n and sorted_stream[i][1] == 0x9D:
group['pop_addr'] = sorted_stream[i][0]
i += 1
groups.append(group)
else:
i += 1
return groups
def disassemble_value(value, size):
b = value.to_bytes(size, byteorder='little')
for insn in md.disasm(b, 0x1000):
return f"{insn.mnemonic} {insn.op_str}"
return ""
def combine_and_decode_group(group, stream_dict):
xor_list = sorted(group['xor_list'], key=lambda x: x['effective_addr'])
combined_bytes = b""
for entry in xor_list:
size = 4 if entry['type'] == 'dword' else (2 if entry['type'] == 'word' else 1)
raw_bytes = bytes([stream_dict.get(entry['effective_addr'] + i, 0) for i in range(size)])
orig_val = int.from_bytes(raw_bytes, 'little')
decoded_val = orig_val ^ entry['imm']
decoded_bytes = decoded_val.to_bytes(size, 'little')
combined_bytes += decoded_bytes
return combined_bytes
def generate_new_xor_instructions(combined_bytes, new_base):
new_lines = []
offset = 0
addr = new_base
length = len(combined_bytes)
while offset < length:
remaining = length - offset
if remaining >= 4:
chunk_size = 4
chunk = combined_bytes[offset:offset+chunk_size]
val = int.from_bytes(chunk, 'little')
new_lines.append(f"xor cs:dword_{addr:04X}, 0x{val:08X}")
elif remaining >= 2:
chunk_size = 2
chunk = combined_bytes[offset:offset+chunk_size]
val = int.from_bytes(chunk, 'little')
new_lines.append(f"xor cs:word_{addr:04X}, 0x{val:04X}")
else:
chunk_size = 1
chunk = combined_bytes[offset:offset+chunk_size]
val = chunk[0]
new_lines.append(f"xor cs:byte_{addr:04X}, 0x{val:02X}")
offset += chunk_size
addr += chunk_size
return new_lines
def generate_assembly_new(groups, stream_dict, new_base=0x2136):
lines = []
lines2 = []
for grp in groups:
combined_bytes = combine_and_decode_group(grp, stream_dict)
disasm = ""
for insn in md.disasm(combined_bytes, 0x1000):
disasm = f"{insn.mnemonic} {insn.op_str}"
break
if disasm:
lines.append(disasm)
new_xor_lines = generate_new_xor_instructions(combined_bytes, new_base)
lines2.extend(new_xor_lines)
return lines
def deduplicate_lines(lines):
deduped = []
for line in lines:
if deduped and deduped[-1] == line:
continue
deduped.append(line)
return deduped
def main():
data_bytes = [
0xF3, 0x0F, 0x1E, 0xFA, 0x55, 0x48, 0x89, 0xE5, 0x90, ...
#篇幅原因只显示这些
]
base_addr = 0x43D0
stream_dict, sorted_stream = parse_bytes(data_bytes, base_addr)
groups = extract_pushfq_group(sorted_stream)
new_asm_lines = generate_assembly_new(groups, stream_dict, new_base=0x2136)
new_asm_lines = deduplicate_lines(new_asm_lines)
for line in new_asm_lines:
print(line)
if __name__ == "__main__":
main()
这样就可以把加密的代码给恢复回来了
动调可以发现核心代码在43D0-8FD0
那么把43D0-8FD0的代码恢复一下
endbr64
push rbp
mov rbp, rsp
sub rsp, 0x2a0
mov rax, qword ptr fs:[0x28]
mov qword ptr [rbp - 8], rax
xor eax, eax
mov qword ptr [rbp - 0x210], 0
mov qword ptr [rbp - 0x208], 0
mov qword ptr [rbp - 0x200], 0
mov qword ptr [rbp - 0x1f8], 0
mov qword ptr [rbp - 0x1f0], 0
mov qword ptr [rbp - 0x1e8], 0
mov qword ptr [rbp - 0x1e0], 0
mov qword ptr [rbp - 0x1d8], 0
mov qword ptr [rbp - 0x1d0], 0
mov qword ptr [rbp - 0x1c8], 0
mov qword ptr [rbp - 0x1c0], 0
mov qword ptr [rbp - 0x1b8], 0
mov qword ptr [rbp - 0x1b0], 0
mov qword ptr [rbp - 0x1a8], 0
mov qword ptr [rbp - 0x1a0], 0
mov qword ptr [rbp - 0x198], 0
mov qword ptr [rbp - 0x190], 0
mov qword ptr [rbp - 0x188], 0
mov qword ptr [rbp - 0x180], 0
mov qword ptr [rbp - 0x178], 0
mov qword ptr [rbp - 0x170], 0
mov qword ptr [rbp - 0x168], 0
mov qword ptr [rbp - 0x160], 0
mov qword ptr [rbp - 0x158], 0
mov qword ptr [rbp - 0x150], 0
mov qword ptr [rbp - 0x148], 0
mov qword ptr [rbp - 0x140], 0
mov qword ptr [rbp - 0x138], 0
mov qword ptr [rbp - 0x130], 0
mov qword ptr [rbp - 0x128], 0
mov qword ptr [rbp - 0x120], 0
mov qword ptr [rbp - 0x118], 0
mov qword ptr [rbp - 0x110], 0
mov qword ptr [rbp - 0x108], 0
mov qword ptr [rbp - 0x100], 0
mov qword ptr [rbp - 0xf8], 0
mov qword ptr [rbp - 0xf0], 0
mov qword ptr [rbp - 0xe8], 0
mov qword ptr [rbp - 0xe0], 0
mov qword ptr [rbp - 0xd8], 0
mov qword ptr [rbp - 0xd0], 0
mov qword ptr [rbp - 0xc8], 0
mov qword ptr [rbp - 0xc0], 0
mov qword ptr [rbp - 0xb8], 0
mov qword ptr [rbp - 0xb0], 0
mov qword ptr [rbp - 0xa8], 0
mov qword ptr [rbp - 0xa0], 0
mov qword ptr [rbp - 0x98], 0
mov qword ptr [rbp - 0x90], 0
mov qword ptr [rbp - 0x88], 0
mov qword ptr [rbp - 0x80], 0
mov qword ptr [rbp - 0x78], 0
mov qword ptr [rbp - 0x70], 0
mov qword ptr [rbp - 0x68], 0
mov qword ptr [rbp - 0x60], 0
mov qword ptr [rbp - 0x58], 0
mov qword ptr [rbp - 0x50], 0
mov qword ptr [rbp - 0x48], 0
mov qword ptr [rbp - 0x40], 0
mov qword ptr [rbp - 0x38], 0
mov qword ptr [rbp - 0x30], 0
mov qword ptr [rbp - 0x28], 0
mov qword ptr [rbp - 0x20], 0
mov qword ptr [rbp - 0x18], 0
lea rax, [rbp - 0x270]
mov edx, 4
mov esi, 4
mov rdi, rax
call 0xffffffffffffce8f
lea rax, [rbp - 0x250]
mov edx, 4
mov esi, 4
mov rdi, rax
call 0xffffffffffffcda8
lea rax, [rbp - 0x230]
mov edx, 4
mov esi, 4
mov rdi, rax
call 0xffffffffffffccc1
lea rax, [rbp - 0x270]
mov ecx, 0x58
mov edx, 0
mov esi, 0
mov rdi, rax
call 0xffffffffffffd50f
lea rax, [rbp - 0x270]
mov rcx, 0xffffffffffffffef
mov edx, 1
mov esi, 0
mov rdi, rax
call 0xffffffffffffd3e9
lea rax, [rbp - 0x270]
mov ecx, 0x13
mov edx, 2
mov esi, 0
mov rdi, rax
call 0xffffffffffffd2d7
lea rax, [rbp - 0x270]
mov rcx, 0xffffffffffffffc7
mov edx, 3
mov esi, 0
mov rdi, rax
call 0xffffffffffffd1b1
lea rax, [rbp - 0x270]
mov ecx, 0x2d
mov edx, 0
mov esi, 1
mov rdi, rax
call 0xffffffffffffd09f
lea rax, [rbp - 0x270]
mov rcx, 0xfffffffffffffff7
mov edx, 1
mov esi, 1
mov rdi, rax
call 0xffffffffffffcf79
lea rax, [rbp - 0x270]
mov ecx, 0xa
mov edx, 2
mov esi, 1
mov rdi, rax
call 0xffffffffffffce67
lea rax, [rbp - 0x270]
mov rcx, 0xffffffffffffffe3
mov edx, 3
mov esi, 1
mov rdi, rax
call 0xffffffffffffcd41
lea rax, [rbp - 0x270]
mov rcx, 0xffffffffffffffc8
mov edx, 0
mov esi, 2
mov rdi, rax
call 0xffffffffffffcc1b
lea rax, [rbp - 0x270]
mov ecx, 0xb
mov edx, 1
mov esi, 2
mov rdi, rax
call 0xffffffffffffcb09
lea rax, [rbp - 0x270]
mov rcx, 0xfffffffffffffff4
mov edx, 2
mov esi, 2
mov rdi, rax
call 0xffffffffffffc9e3
lea rax, [rbp - 0x270]
mov ecx, 0x24
mov edx, 3
mov esi, 2
mov rdi, rax
call 0xffffffffffffc8d1
lea rax, [rbp - 0x270]
mov rcx, 0xffffffffffffffd8
mov edx, 0
mov esi, 3
mov rdi, rax
call 0xffffffffffffc7ab
lea rax, [rbp - 0x270]
mov ecx, 8
mov edx, 1
mov esi, 3
mov rdi, rax
call 0xffffffffffffc699
lea rax, [rbp - 0x270]
mov rcx, 0xfffffffffffffff7
mov edx, 2
mov esi, 3
mov rdi, rax
call 0xffffffffffffc573
lea rax, [rbp - 0x270]
mov ecx, 0x1a
mov edx, 3
mov esi, 3
mov rdi, rax
call 0xffffffffffffc461
lea rax, [rip + 0x15b6e]
mov rdi, rax
call 0xffffffffffffb3b0
lea rax, [rip + 0x15b2d]
mov rdi, rax
call 0xffffffffffffb31f
mov rax, qword ptr [rip + 0x18194]
mov rdi, rax
call 0xffffffffffffb28e
lea rax, [rip + 0x15a5b]
mov rdi, rax
mov eax, 0
call 0xffffffffffffb212
lea rax, [rbp - 0x210]
mov edx, 0x100
mov rsi, rax
mov edi, 0
call 0xffffffffffffb15b
mov dword ptr [rbp - 0x27c], eax
cmp dword ptr [rbp - 0x27c], 0
mov eax, dword ptr [rbp - 0x27c]
sub eax, 1
cdqe
movzx eax, byte ptr [rbp + rax - 0x210]
cmp al, 0xa
mov eax, dword ptr [rbp - 0x27c]
sub eax, 1
cdqe
mov byte ptr [rbp + rax - 0x210], 0
lea rax, [rbp - 0x210]
mov rdi, rax
call 0xffffffffffffd35d
cmp rax, 0x13
mov eax, 0
call 0xffffffffffffdacb
mov dword ptr [rbp - 0x294], 0
mov byte ptr [rbp - 0x296], 1
mov dword ptr [rbp - 0x290], 0
mov edx, dword ptr [rbp - 0x290]
movsxd rax, edx
imul rax, rax, 0x66666667
shr rax, 0x20
sar eax, 1
mov ecx, edx
sar ecx, 0x1f
sub eax, ecx
mov ecx, eax
shl ecx, 2
add ecx, eax
mov eax, edx
sub eax, ecx
cmp eax, 4
movzx edx, byte ptr [rbp - 0x296]
mov eax, dword ptr [rbp - 0x290]
cdqe
movzx eax, byte ptr [rbp + rax - 0x210]
cmp al, 0x2d
sete al
movzx eax, al
and eax, edx
test eax, eax
setne al
mov byte ptr [rbp - 0x296], al
mov eax, dword ptr [rbp - 0x294]
lea edx, [rax + 1]
mov dword ptr [rbp - 0x294], edx
mov edx, dword ptr [rbp - 0x290]
movsxd rdx, edx
movzx edx, byte ptr [rbp + rdx - 0x210]
cdqe
mov byte ptr [rbp + rax - 0x110], dl
movzx edx, byte ptr [rbp - 0x296]
mov eax, dword ptr [rbp - 0x290]
cdqe
movzx eax, byte ptr [rbp + rax - 0x210]
cmp al, 0x40
mov eax, dword ptr [rbp - 0x290]
cdqe
movzx eax, byte ptr [rbp + rax - 0x210]
cmp al, 0x5a
mov eax, 1
mov eax, 0
and eax, edx
test eax, eax
setne al
mov byte ptr [rbp - 0x296], al
add dword ptr [rbp - 0x290], 1
cmp dword ptr [rbp - 0x290], 0x12
movzx eax, byte ptr [rbp - 0x296]
xor eax, 1
test al, al
mov eax, 0
call 0xffffffffffffcff1
mov dword ptr [rbp - 0x28c], 0
mov dword ptr [rbp - 0x288], 0
mov eax, dword ptr [rbp - 0x28c]
lea edx, [rax*4]
mov eax, dword ptr [rbp - 0x288]
add eax, edx
cdqe
movzx eax, byte ptr [rbp + rax - 0x110]
movsx eax, al
lea edx, [rax - 0x41]
mov eax, dword ptr [rbp - 0x28c]
imul eax, dword ptr [rbp - 0x288]
mov ecx, eax
mov eax, edx
sub eax, ecx
movsxd rcx, eax
mov eax, dword ptr [rbp - 0x288]
movsxd rdx, eax
mov eax, dword ptr [rbp - 0x28c]
movsxd rsi, eax
lea rax, [rbp - 0x250]
mov rdi, rax
call 0xffffffffffffae52
add dword ptr [rbp - 0x288], 1
cmp dword ptr [rbp - 0x288], 3
add dword ptr [rbp - 0x28c], 1
cmp dword ptr [rbp - 0x28c], 3
mov byte ptr [rbp - 0x295], 1
lea rdx, [rbp - 0x230]
lea rcx, [rbp - 0x250]
lea rax, [rbp - 0x270]
mov rsi, rcx
mov rdi, rax
call 0xffffffffffffb031
mov dword ptr [rbp - 0x284], 0
mov dword ptr [rbp - 0x280], 0
mov eax, dword ptr [rbp - 0x280]
movsxd rdx, eax
mov eax, dword ptr [rbp - 0x284]
movsxd rsi, eax
lea rcx, [rbp - 0x278]
lea rax, [rbp - 0x230]
mov rdi, rax
call 0xffffffffffffa43d
mov eax, dword ptr [rbp - 0x284]
cmp eax, dword ptr [rbp - 0x280]
movzx edx, byte ptr [rbp - 0x295]
mov rax, qword ptr [rbp - 0x278]
cmp rax, 1
sete al
movzx eax, al
and eax, edx
test eax, eax
setne al
mov byte ptr [rbp - 0x295], al
movzx edx, byte ptr [rbp - 0x295]
mov rax, qword ptr [rbp - 0x278]
test rax, rax
sete al
movzx eax, al
and eax, edx
test eax, eax
setne al
mov byte ptr [rbp - 0x295], al
add dword ptr [rbp - 0x280], 1
cmp dword ptr [rbp - 0x280], 3
add dword ptr [rbp - 0x284], 1
cmp dword ptr [rbp - 0x284], 3
cmp byte ptr [rbp - 0x295], 0
lea rax, [rbp - 0x210]
mov rdi, rax
call 0xffffffffffffc15d
mov eax, 0
call 0xffffffffffffbfbf
mov rax, qword ptr [rbp - 8]
sub rax, qword ptr fs:[0x28]
call 0xffffffffffff91e9
leave
查看汇编代码可以发现flag长度为19
里面有一个4x4的矩阵Matrix1
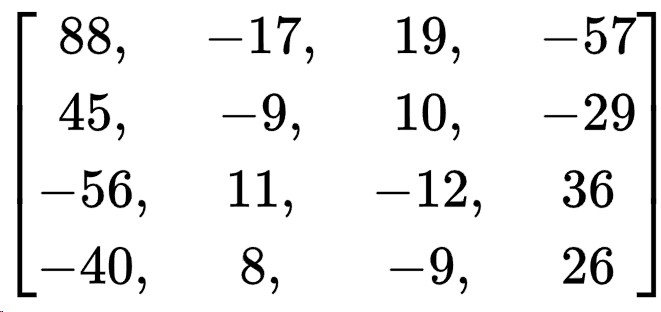
核心逻辑就是由输入字符串的大写字母生成 Matrix2
格式是XXXX-XXXX-XXXX-XXXX
转换规则为 Matrix2[j][k] = (InputChar[j][k] - 'A') - (j * k)
然后让两个矩阵相乘看看结果是不是单位矩阵
那么Matrix2就是Matrix1的逆矩阵,求出逆矩阵后求解即可
exp:
import numpy as np
import sys
matrix1_values = [
[ 88, -17, 19, -57],
[ 45, -9, 10, -29],
[-56, 11, -12, 36],
[-40, 8, -9, 26]
]
matrix1 = np.array(matrix1_values, dtype=np.float64)
print("Matrix1:")
print(matrix1)
print("-" * 20)
try:
matrix2_target = np.linalg.inv(matrix1)
print("Matrix2:")
print(matrix2_target)
print("-" * 20)
except np.linalg.LinAlgError:
print("错误: Matrix1 是奇异矩阵 (不可逆).")
sys.exit(1)
input_chars = []
valid = True
for j in range(4):
for k in range(4):
target_val = matrix2_target[j, k]
rounded_val = round(target_val)
char_code_float = rounded_val + (j * k) + ord('A')
char_code = int(char_code_float)
char = chr(char_code)
input_chars.append(char)
final_input = f"{''.join(input_chars[0:4])}-{''.join(input_chars[4:8])}-{''.join(input_chars[8:12])}-{''.join(input_chars[12:16])}"
print(final_input)
得到密码:BFCF-EJJL-CKKL-BLJQ
输入密码即可得到flag

嗯......这题挺烦的,做了几个小时(主要是写脚本和看汇编),一开始以为只是简单是SMC,结果运行完发现数据块没变 🤡
最后附上官方WP的反混淆器 他是返回的等效的二进制文件,可以拖到IDA或BN里去分析,就不用自己去看汇编了
from pwn import *
import capstone
import sys
import ctypes
def xor(a, b):
return bytes([a ^ b for a, b in zip(a, b)])
def disas_single(data):
disas = capstone.Cs(capstone.CS_ARCH_X86, capstone.CS_MODE_64)
inst = next(disas.disasm(data, 0))
return inst, inst.size, inst.mnemonic
def deobufscate(elf, code, text_off, text_end, addr, modified):
stop = False
while not stop:
inst, sz, mneumonic = disas_single(code[addr:])
if mneumonic == 'ret':
stop = True
elif mneumonic == 'call':
call_dst = addr + ctypes.c_int64(int(inst.op_str, 16)).value
if call_dst >= text_off and call_dst <= text_end:
deobufscate(elf, code, text_off, text_end, call_dst, modified)
elif mneumonic == 'xor':
if '[rip + ' in inst.op_str:
rip_rel = int(inst.op_str.split('[rip + ')[1].split(']')[0], 16)
key = int(inst.op_str.split(',')[1], 16)
decrypt = b''
if inst.op_str.startswith('qword ptr '):
decrypt = xor(p64(key), code[addr + sz + rip_rel: addr + sz + rip_rel + 8])
elif inst.op_str.startswith('dword ptr '):
decrypt = xor(p32(key), code[addr + sz + rip_rel: addr + sz + rip_rel + 4])
elif inst.op_str.startswith('word ptr '):
decrypt = xor(p16(key), code[addr + sz + rip_rel: addr + sz + rip_rel + 2])
elif inst.op_str.startswith('byte ptr '):
decrypt = xor(p8(key), code[addr + sz + rip_rel: addr + sz + rip_rel + 1])
assert(len(decrypt) in [1, 2, 4, 8])
for i, b in enumerate(decrypt):
modified[addr + sz + rip_rel + i] = b
for i in range(addr, addr + sz):
modified[i] = 0x90
if code[addr - 0x1] == 0x9c:
modified[addr - 0x1] = 0x90
if code[addr + sz] == 0x9d:
modified[addr + sz] = 0x90
elif '[rip -' in inst.op_str:
for i in range(addr, addr + sz):
modified[i] = 0x90
if code[addr - 0x1] == 0x9c:
modified[addr - 0x1] = 0x90
if code[addr + sz] == 0x9d:
modified[addr + sz] = 0x90
code = bytes(modified)
addr += sz
if __name__ == '__main__':
if len(sys.argv) != 3:
print(f'{sys.argv[0]} obfuscated main_offset')
exit(1)
elf = ELF(sys.argv[1])
main = int(sys.argv[2], 16)
text_off = elf.get_section_by_name('.text').header.sh_offset
text_end = elf.get_section_by_name('.text').header.sh_offset + elf.get_section_by_name('.text').header.sh_size
sz = text_off + text_end
with open(elf.path, 'rb') as f:
full = f.read()
data = full[:sz]
modified = bytearray(data)
deobufscate(elf, data, text_off, text_end, main, modified)
with open(f'{elf.path}_deobfuscate', 'wb') as f:
f.write(bytes(modified) + full[sz:])
gateway
初步分析
该二进制文件是静态链接且被剥离(stripped)的。在当今时代,有了 IDA FLARE 签名或 Binary Ninja sigkit,这真的不应该是个问题。此外,这个挑战中并没有大量使用库函数。可以在 _start 函数中找到 main 函数,因为 _start 中的最后一个调用实际上是 __libc_start_main(main, ...)。这使得 main 函数位于 sub_8049b7c。
不幸的是,在 Binary Ninja(以及 IDA)中,该函数进行到一半时,反编译结果看起来非常糟糕。
08049b7c int32_t sub_8049b7c()
08049b83 void* const __return_addr_1 = __return_addr
08049b86 int32_t ebp
08049b86 int32_t var_8 = ebp
08049b8c void* var_18 = &arg_4
08049b9e void* gsbase
08049b9e int32_t eax = *(gsbase + 0x14) // 栈保护 Canary
08049ba4 int32_t var_24 = eax
08049ba7 bool p = unimplemented {xor eax, eax} // 标志位 p
08049ba7 bool a = undefined // 标志位 a
08049ba9 int32_t var_a4 = 0
08049bc5 void s_2
08049bc5 __builtin_memset(s: &s_2, c: 0, n: 0x7c)
08049bd9 void s_1
08049bd9 __builtin_memset(s: &s_1, c: 0, n: 0x80)
08049bf0 void var_124
08049bf0 int32_t ecx
08049bf0 int32_t esi
08049bf0 int32_t edi
08049bf0 edi, esi, ecx = __builtin_memcpy(dest: &var_124, src: &data_80de860, n: 0x80)
08049bf2 int32_t s
08049bf2 __builtin_memset(&s, c: 0, n: 0x18)
08049c34 int32_t* var_1e4 = &s
08049c34 int32_t var_1e8 = ecx
08049c34 void* const var_1ec = &data_80de860
08049c34 int32_t* var_1f0 = &data_8114000
08049c34 int32_t** var_1f4 = &var_1f0
08049c34 int32_t* var_1f8 = &var_8
08049c34 int32_t var_1fc = esi
08049c34 int32_t var_200 = edi
08049c35 bool d // 标志位 d
08049c35 int32_t var_204 = (0 ? 1 : 0) << 0xb | (d ? 1 : 0) << 0xa | (0 s< 0 ? 1 : 0) << 7 | (eax == eax ? 1 : 0) << 6 | (a ? 1 : 0) << 4 | (p ? 1 : 0) << 2 | (0 ? 1 : 0) // EFLAGS
08049c38 int32_t var_208 = 0x23 // CS for 32-bit
08049c40 int32_t (* var_20c)(int32_t arg1, int32_t arg2, void* arg3, int32_t* arg4, int32_t arg5, int32_t arg6) = sub_8049c4b // Return EIP (32-bit)
08049c41 int32_t var_210 = 0x33 // CS for 64-bit
08049c49 int32_t (* var_214)() = sub_80499b9 // Target EIP (64-bit)
08049c4a undefined
混淆分析
是时候查看反汇编代码了。
08049bf2 c78544feffff0000… mov dword [ebp-0x1bc {s}], 0x0
08049bfc c78548feffff0000… mov dword [ebp-0x1b8 {var_1c0}], 0x0
08049c06 c7854cfeffff0000… mov dword [ebp-0x1b4 {var_1bc}], 0x0
08049c10 c78550feffff0000… mov dword [ebp-0x1b0 {var_1b8}], 0x0
08049c1a c78554feffff0000… mov dword [ebp-0x1ac {var_1b4}], 0x0
08049c24 c78558feffff0000… mov dword [ebp-0x1a8 {var_1b0}], 0x0
08049c2e 8d8544feffff lea eax, [ebp-0x1bc {s}] ; eax 指向 context 结构体
08049c34 60 pushad {var_1e4} {s} {var_1e8} {var_1ec} {var_1f0} {var_1f4} {var_1f0} {var_1f8} {var_8} {var_1fc} {var_200} {data_80de860} {data_8114000} ; 保存通用寄存器
08049c35 9c pushfd {var_204} ; 保存 EFLAGS
08049c36 89c3 mov ebx, eax {s} ; ebx 保存 context 结构体指针
08049c38 6a23 push 0x23 {var_208} ; 压入 32 位 CS 段选择子 (用于返回)
08049c3a 8d054b9c0408 lea eax, [sub_8049c4b]
08049c40 50 push eax {var_20c} {sub_8049c4b} ; 压入 32 位返回地址
08049c41 6a33 push 0x33 {var_210} ; 压入 64 位 CS 段选择子
08049c43 8d05b9990408 lea eax, [sub_80499b9]
08049c49 50 push eax {var_214} {sub_80499b9} ; 压入 64 位目标地址
08049c4a cb ret far ; 远返回指令,切换到 64 位模式
08049c4b int32_t sub_8049c4b(int32_t arg1, int32_t arg2, void* arg3, int32_t* arg4, int32_t arg5, int32_t arg6)
08049c4b 9d popfd {__return_addr} ; 恢复 EFLAGS
08049c4c 61 popad {arg1} {arg2} {arg3} {arg4} {arg5} {arg6} {arg_20} ; 恢复通用寄存器
在这里,一些值被移入一个 context 结构体,该结构体的地址保存在 ebx 中。然后,程序将所有通用寄存器和 eflags 寄存器压入栈中。它还将 0x23、sub_8049c4b 的地址、0x33、sub_80499b9 的地址压入栈中。注意,sub_8049c4b 期望栈顶是 eflags 的值,然后恢复 eflags 和通用寄存器。接着,使用了一个 ret far 指令。
根据 x86 文档,ret far 从栈中弹出两项——返回地址和代码段地址。在 Linux 上,CS 寄存器 决定了程序是在兼容模式(32位)还是 64 位模式下执行。值为 0x23 会使程序在 32 位模式下执行,而值为 0x33 会使程序在 64 位模式下执行。因此,ret far 将控制流转移到 64 位模式下的 sub_80499b9。
该函数的反编译看起来相当合理:
080499b9 int32_t sub_80499b9()
080499fd sub_80497b5() // 看起来调用了这个函数
08049a02 return &data_8114000 // 返回一个地址
080497b5 int32_t sub_80497b5()
080497c2 data_811531c = 0x1337
080497ce return &data_8114000
但是为什么 sub_80499b9 对于如此简单的操作却有这么大的函数体呢?让我们观察一下汇编代码:
080499b9 int32_t sub_80499b9()
080499b9 e8a9050000 call sub_8049f67
080499be 0542a60c00 add eax, 0xca642 {data_8114000}
080499c3 31c0 xor eax, eax
080499c5 40 inc eax {0x0}
080499c6 7535 jne 0x80499fd {0x1} ; 32位下总会跳转
080499c8 89631c mov dword [ebx+0x1c], esp {__return_addr} {data_811401c}
080499cb 48 dec eax ; 48 在 64 位下是 REX.W 前缀
080499cc 83ec10 sub esp, 0x10
080499cf 48 dec eax ; REX.W 前缀
080499d0 c7c00f000000 mov eax, 0xf
080499d6 48 dec eax ; REX.W 前缀
080499d7 f7d0 not eax
080499d9 48 dec eax ; REX.W 前缀
080499da 21c4 and esp, eax
080499dc 8b3b mov edi, dword [ebx] {data_8114000}
080499de 8b7304 mov esi, dword [ebx+0x4] {data_8114004}
080499e1 8b5308 mov edx, dword [ebx+0x8] {data_8114008}
080499e4 8b4b0c mov ecx, dword [ebx+0xc] {data_811400c}
080499e7 44 inc esp ; 44 在 64 位下是 REX.R 前缀
080499e8 8b4310 mov eax, dword [ebx+0x10] {data_8114010}
080499eb 44 inc esp ; REX.R 前缀
080499ec 8b4b14 mov ecx, dword [ebx+0x14] {data_8114014}
080499ef 53 push ebx {var_12} {data_8114000}
080499f0 e848060000 call sub_804a03d ; 实际调用的函数
080499f5 5b pop ebx {var_12} {data_8114000}
080499f6 894318 mov dword [ebx+0x18], eax {data_8114018} ; 保存返回值
080499f9 8b631c mov esp, dword [ebx+0x1c] {data_811401c} ; 恢复栈指针
080499fc cb ret far ; 返回 32 位模式
080499fd e8b3fdffff call sub_80497b5 ; 伪装调用的函数
08049a02 c3 retn {__return_addr}
这个反汇编看起来有点不合逻辑。以下序列将总是导致 jne 分支被执行(在32位视角下):
080499c3 31c0 xor eax, eax
080499c5 40 inc eax {0x0}
080499c6 7535 jne 0x80499fd {0x1}
为什么反汇编看起来这么奇怪?这是因为多语言代码混淆了反汇编器和反编译器。实际上,这个多语言序列是 一个著名的 32 位/64 位多语言代码示例,它导致代码在两种架构下的行为不同,但在两种架构下都能有效地反汇编。将此函数反汇编为 64 位会更有意义,因为我们现在处于 64 位模式:
080499b9 uint64_t sub_80499b9(int32_t* arg1 @ rbx) ; rbx 指向 context 结构体
080499b9 e8a9050000 call sub_8049f67 ; PIC 相关调用
080499be 0542a60c00 add eax, 0xca642 ; PIC 相关修正
080499c3 31c0 xor eax, eax {0x0}
080499c5 407535 jne 0x80499fd {0x0} ; 40 是 jne 的 REX 前缀,jne 不会跳转 (ZF=1)
080499c8 89631c mov dword [rbx+0x1c], esp {__return_addr} ; 保存旧 esp (32位) 到 context
080499cb 4883ec10 sub rsp, 0x10 ; 栈对齐
080499cf 48c7c00f000000 mov rax, 0xf
080499d6 48f7d0 not rax {0xfffffffffffffff0}
080499d9 4821c4 and rsp, rax ; 进一步栈对齐 (16 字节)
080499dc 8b3b mov edi, dword [rbx] ; 从 context 加载参数到 rdi (arg1)
080499de 8b7304 mov esi, dword [rbx+0x4] ; rsi (arg2)
080499e1 8b5308 mov edx, dword [rbx+0x8] ; rdx (arg3)
080499e4 8b4b0c mov ecx, dword [rbx+0xc] ; rcx (arg4)
080499e7 448b4310 mov r8d, dword [rbx+0x10] ; r8 (arg5)
080499eb 448b4b14 mov r9d, dword [rbx+0x14] ; r9 (arg6)
080499ef 53 push rbx {var_18} ; 保存 rbx
080499f0 e848060000 call sub_804a03d ; 调用实际的 64 位函数
080499f5 5b pop rbx {var_18} ; 恢复 rbx
080499f6 894318 mov dword [rbx+0x18], eax {0xfeedfacecafebabe} ; 将返回值 eax 保存到 context
080499f9 8b631c mov esp, dword [rbx+0x1c] ; 恢复旧的 32 位 esp
080499fc cb ret far ; 远返回,切换回 32 位模式 (栈上有 0x23 和 sub_8049c4b)
080499fd e8b3fdffff call sub_80497b5 ; 伪装的调用 (永远不会执行)
08049a02 c3 retn {__return_addr}
inc eax 的编码是 0x40,在 x86_64 上,它充当 jcc 指令的 REX 前缀,对跳转没有影响。重复调用 sub_8049f67 只是以下内容:
08049f67 void* const sub_8049f67() __pure
08049f67 8b0424 mov eax, dword [esp {__return_addr}] ; 获取 call 指令之后的地址
08049f6a c3 retn {__return_addr}
这是 32 位二进制文件用于位置无关代码(PIC)的常见模式 - 这是该 crackme 编译和链接方式的产物,但在 64 位模式下仍然可以正常工作。
sub_804a03d 看起来如下(如果不视为 64 位代码,反汇编/反编译将再次看起来不正确):
0804a03d void sub_804a03d() // 实际的 64 位函数 (设置 PRNG 种子)
0804a04f data_8115320 = -0x3501454121524111 // 0xcafebabedeadbeefULL
0804a060 data_8115328 = -0x112053135014542 // 0xfeedfacecafebabeULL
0804a067 data_8115330 = 1 // rounds = 1
总之,上面有效的反汇编序列重新对齐了堆栈,将旧的堆栈值存储到 context 结构体中,从 rbx 寄存器先前指向的 context 结构体中设置寄存器值,调用一个函数,将返回值(rax 寄存器)再次保存到 context 结构体中,恢复堆栈寄存器,并再次调用 ret far。回想一下,此时栈顶是 sub_8049c4b 的地址和 0x23,允许程序返回到 32 位模式执行。寄存器值对应于 amd64 上的 SYSV ABI 调用约定,因此 context 结构体实际上是 ret far 转换来回传递参数和返回值的一种方式。
这些转换汇编序列在整个程序中重复出现,用于进入 64 位代码。通常,每个序列都有一个伪函数和真函数,如上所示(这里的伪函数是 sub_80497b5,真函数是 sub_804a03d),用这种反反汇编/反反编译陷阱欺骗粗心的逆向工程师。
清理分析
既然我们理解了这个 Heavensgate 序列,让我们执行一些修补(patching)来帮助清理这个 Heavensgate 序列。浏览 main 函数,我们知道这个序列大多是内联的,但只发生几次。回想一下,首先 ret far 跳转到一个 64 位函数存根(stub),然后从那里调用真正的函数。我们可以直接修补二进制文件,使得在导致 ret far 的存根中直接进行 call,并将其他序列用 nop 填充掉。我将上述序列修补为仅调用真实函数,如下所示:
08049bf2 e846040000 call seed_804a03d ; 直接调用 64 位种子函数
08049bf7 90 nop
08049bf8 90 nop
08049bf9 90 nop
08049bfa 90 nop
08049bfb 90 nop
08049bfc 90 nop
08049bfd 90 nop
; ... 原来的 pushad, pushfd, push 等指令被 NOP 掉 ...
有时,程序会使用 context 结构体的返回值设置 eax 的值,这也可能需要为反编译器修补掉。
下一个转换序列发生在 08049ccd,其中真正的函数位于 sub_8049fd3,伪函数位于 sub_80769d0。真正的函数在 64 位模式下进行 read 系统调用(伪函数只是执行一个 read 库调用)。我将其修补为以下序列,以模拟调用约定的差异(SYSV ABI 使用 rdi, rsi, rdx):
mov edi, 0 ; fd = 0 (stdin)
lea esi, [ebp - 0x9c] ; buf = buffer address
mov edx, 0x80 ; count = 0x80
call sub_8049fd3 ; 调用 64 位 read syscall 包装函数
请注意,Binary Ninja 在处理跨架构调用时似乎有点挑剔 - 我必须先在 64 位模式下检查反编译版本,然后切换回 32 位模式,并手动更改调用约定,以使调用者的反编译看起来正确。否则,调用者中的函数将总是显示不带参数。
另一个 Heavensgate 转换发生在 08049d6e。伪函数位于 sub_80497fc,而真正的函数位于 sub_804a118:
// 伪函数 (32 位)
080497fc uint32_t sub_80497fc(char arg1)
08049815 uint8_t var_8_2 = not.b(arg1) ^ 0x5a
08049829 uint8_t eax_4 = var_8_2 << 4 | var_8_2 u>> 4
0804983e uint8_t eax_8 = eax_4 u>> 5 | eax_4 << 3
08049861 return zx.d(((eax_8 * 2) & 0xaa) | ((zx.d(eax_8) s>> 1).b & 0x55))
// 真函数 (64 位) - 简单的字节变换 (交换奇偶位)
0804a118 uint64_t sub_804a118(char arg1) __pure
0804a125 int64_t var_10 = 0
0804a150 return zx.q((zx.d(arg1) * 2) & 0xaa) | zx.q(zx.d(arg1) u>> 1 & 0x55)
// 等价于: return ((arg1 & 0x55) << 1) | ((arg1 & 0xAA) >> 1);
这两个都是简单的字节变换函数。真函数的作用是交换字节内奇数位和偶数位的位置。
它接受一个参数(在 32 位中是 eax,在 64 位中是 edi),所以我将这个序列修补为:
mov edi, eax ; 将 32 位参数 eax 放入 64 位参数 edi
call sub_804a118 ; 调用 64 位字节变换函数
另一个序列发生在 08049e29。伪函数位于 sub_8049862,真函数位于 sub_804a151:
// 伪函数 (CRC32)
08049862 int32_t sub_8049862(int32_t arg1, int32_t arg2) // arg1=ptr, arg2=len
08049872 uint32_t var_10 = 0xffffffff
08049872
080498cc for (void* i = nullptr; i u< arg2; i += 1)
08049890 var_10 ^= zx.d(*(i + arg1))
08049890
080498c0 for (int32_t j = 0; j u<= 7; j += 1)
080498a4 if ((var_10 & 1) == 0)
080498b5 var_10 u>>= 1
080498a4 else
080498b0 var_10 = var_10 u>> 1 ^ 0xedb88320 // CRC32 polynomial
080498b0
080498d4 return not.d(var_10)
// 真函数 (CRC64 variant)
0804a151 int64_t sub_804a151(int64_t arg1, int64_t arg2) // arg1=ptr, arg2=len
0804a161 uint64_t var_20 = -1 // 0xFFFFFFFFFFFFFFFF
0804a161
0804a1d8 for (void* i = nullptr; i u< arg2; i += 1)
0804a184 var_20 ^= zx.q(*(i + arg1))
0804a184
0804a1c9 for (int64_t j = 0; j u<= 7; j += 1)
0804a19c if (zx.q(var_20.d & 1) == 0)
0804a1bb var_20 u>>= 1
0804a19c else
0804a1b5 var_20 = 0xc96c5795d7870f42 ^ var_20 u>> 1 // CRC64-ECMA-182 polynomial
0804a1b5
0804a1e2 return not.q(var_20)
这两个都是 CRC 的变种——伪函数是 CRC32,后者基于使用的常量判断是 CRC64 的一个变种(ECMA-182 多项式)。这些是 CRC 函数的生成性、较慢的版本,而不是使用查找表。
修补结果是这样的(参数 ptr 在 eax,长度在 esi(这里固定为1),64位下对应 rdi 和 rsi):
08049e29 89c7 mov edi, eax ; ptr
08049e2b be01000000 mov esi, 0x1 ; len = 1
08049e30 e81c030000 call sub_804a151 ; 调用 64 位 CRC64 函数
二进制文件中的最后一个 Heavensgate 转换来自 main 函数中的 sub_8049a9d 调用,具体位置在 08049aca。伪函数位于 sub_80497cf,而真函数位于 sub_804a071:
// 伪函数 (简单的线性同余 PRNG)
080497cf int32_t sub_80497cf()
080497ee data_811531c = data_811531c * 0x343fd + 0x269ec3
080497fb return data_811531c
// 真函数 (xorshift128+ PRNG)
0804a071 int64_t sub_804a071()
0804a089 int32_t s
0804a089 __builtin_memset(&s, c: 0, n: 0x14)
0804a106 int64_t result
0804a106 int64_t var_18_1
0804a106
0804a106 for (; s s<= zx.d(data_8115330); s += 1) // data_8115330 是 rounds
0804a092 int64_t rax_1 = data_8115320 // xstate1
0804a09d int64_t rax_2 = data_8115328 // xstate2
0804a0ac data_8115320 = rax_2 // xstate1 = xstate2
0804a0bb int64_t var_18_3 = rax_1 ^ rax_1 << 0x17 // t = xstate1; t ^= t << 23; (Note: 0x17 is 23)
0804a0d7 var_18_1 = var_18_3 ^ var_18_3 u>> 0x11 ^ rax_2 u>> 0x1a ^ rax_2 // t ^= t >> 17; t ^= xstate2 ^ (xstate2 >> 26); (Note: 0x11=17, 0x1a=26)
0804a0df data_8115328 = var_18_1 // xstate2 = t
0804a0f1 result = rax_2 + var_18_1 // result = old_xstate2 + new_xstate2
0804a0f1
0804a10c data_8115330 = var_18_1.b // rounds = t & 0xFF
0804a117 return result
回想一下我们分析的第一个函数(seed_804a03d),以及它们如何引用相似的数据位置。那些第一个函数是种子函数,而这些是伪随机数生成器(PRNG)函数。真函数是 xorshift128+ 算法。我将这最后一个转换修补为直接调用真函数。
sub_8049ad 最终看起来像这样,这是一个简单的洗牌(shuffle)函数:
// 洗牌函数 (Fisher-Yates shuffle 变种)
08049a9d int32_t sub_8049a9d(char* arg1, int32_t arg2) // arg1=buffer, arg2=len
08049ab3 void* gsbase
08049ab3 int32_t eax_1 = *(gsbase + 0x14) // 读取栈 Canary
08049ab3
08049b62 for (void* i = nullptr; i u< arg2; i += 1) // for (i = 0; i < len; i++)
08049b18 uint32_t temp1_1 = modu.dp.d(0:(prng_804a071(i)), arg2) // replace = prng() % len
08049b20 int32_t var_38_1 = 0
08049b2f char eax_7 = arg1[temp1_1] // temp_char = buffer[replace]
08049b43 arg1[temp1_1] = *(i + arg1) // buffer[replace] = buffer[i]
08049b56 *(arg1 + i) = eax_7 // buffer[i] = temp_char
08049b56
08049b73 if (eax_1 == *(gsbase + 0x14)) // 检查栈 Canary
08049b7b return eax_1 - *(gsbase + 0x14) // return 0
08049b7b
08049b75 sub_8079620() // __stack_chk_fail
08049b75 noreturn
分析反混淆后的二进制文件
下面是 main 函数,其中一些变量已清理。由于寄存器调用约定和二进制文件的多语言性质,部分内容仍然有点破碎,但整体流程是清晰的。
08049b7c int80_t main_8049b7c()
08049b83 void* const __return_addr_1 = __return_addr
08049b8c void* var_18 = &arg_4
08049b9e void* gsbase
08049b9e int32_t canary = *(gsbase + 0x14) // 读取栈 Canary
08049ba9 char buffer[0x80] // 输入缓冲区
08049ba9 buffer[0].d = 0
08049bc5 __builtin_memset(s: &buffer[4], c: 0, n: 0x7c)
08049bd9 uint32_t computed_crcs[0x20] // 计算得到的 CRC 值数组 (32 个)
08049bd9 __builtin_memset(s: &computed_crcs, c: 0, n: 0x80)
08049bf0 uint32_t expected_crcs[0x20] // 期望的 CRC 值数组 (从 data_80de860 加载)
08049bf0 __builtin_memcpy(dest: &expected_crcs, src: &data_80de860, n: 0x80)
08049bf2 seed_804a03d() // 调用 PRNG 种子函数
08049c5b print_805abe0(data_8114450, 0) // 打印 banner
08049c6d print_8058b00(data_8114068) // 打印提示信息
08049c7f print_8058b00(&data_80de6a4)
08049c91 print_8058b00(&data_80de6f0)
08049ca3 print_8058b00("And fall down into the mortal re…")
08049cb5 int80_t result = sub_8052700(&data_80de768) // 刷新输出缓冲区
08049cdd int32_t bytes_read = read_8049fd3(fd: 0, &buffer, n: 0x80) // 读取输入 (已修补)
08049d2d char check_flag = 0 // 用于最终比较的标志
08049d2d
08049d2d if (bytes_read == 0x21) // 检查输入长度是否为 33 字节 (包括换行符)
08049d3c buffer[bytes_read - 1] = 0 // 将换行符替换为 null 终止符
08049d44 int32_t input_len = bytes_read - 1 // input_len = 32
08049d44
08049df0 for (int32_t i = 0; i s< input_len; i += 1) // 对每个输入字节
08049dd9 buffer[i] = byte_transform_804a118(&buffer[i.b]) // 应用字节变换 (交换奇偶位) (已修补)
08049dd9
08049e07 shuffle_8049a9d(&buffer, input_len) // 使用 PRNG 洗牌输入缓冲区 (已修补 PRNG 调用)
08049e07
08049ea6 for (int32_t i_1 = 0; i_1 s< input_len; i_1 += 1) // 对洗牌后的每个字节
08049e30 int32_t crc_low32 // CRC64 结果的低 32 位
08049e30 int32_t crc_high32 // CRC64 结果的高 32 位 (未使用)
08049e30 crc_low32, crc_high32 = crc64_804a151(&buffer[i_1], count: 1) // 计算单个字节的 CRC64 (已修补)
08049e8c computed_crcs[i_1] = crc_low32 // 将 CRC64 结果的低 32 位存入数组
08049eac check_flag = 1 // 初始化检查标志为真
08049eac
08049f03 for (int32_t i_2 = 0; i_2 s<= 0x1f; i_2 += 1) // 比较 32 个 CRC 值
08049ee2 int32_t cmp_result
08049ee2 cmp_result.b = computed_crcs[i_2] == expected_crcs[i_2] // 比较计算得到的 CRC 和期望的 CRC
08049eec uint32_t new_check_flag
08049eec new_check_flag.b = (zx.d(cmp_result.b) & zx.d(check_flag)) != 0 // 逻辑与:如果当前比较失败或之前已失败,则为假
08049eef check_flag = new_check_flag.b // 更新检查标志
08049eef
08049f0c if (bytes_read != 0x21 || check_flag == 0) // 如果长度不符或 CRC 检查失败
08049f42 print_8058b00("\x1b[1;31mOof... you used the wr…") // 打印失败信息
08049f0c else // 否则 (长度正确且所有 CRC 匹配)
08049f18 print_8058b00("\x1b[1;32mENCHANTMENT CORRECT! Y…") // 打印成功信息
08049f2a print_8058b00(data_811406c) // 打印 flag (HTB{...})
08049f2a
08049f4d *(gsbase + 0x14) // 读取栈 Canary
08049f4d
08049f54 if (canary == *(gsbase + 0x14)) // 检查栈 Canary 是否匹配
08049f66 return result // 正常返回
08049f66
08049f56 sub_8079620() // 调用 __stack_chk_fail
08049f56 noreturn
程序读取输入,确保其长度为 33 字节(最后一个字节被置为 null)。应用字节变换函数(交换奇偶位),然后使用 PRNG 对输入进行洗牌,接着对每个字节计算 CRC64,并将结果(低32位)与一个预期的答案数组进行比较。
推导 flag
首先,我们编写一些辅助函数来逆转这些操作:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
static uint64_t xstate1;
static uint64_t xstate2;
static uint8_t rounds;
// 初始化 PRNG 状态
void seed() {
xstate1 = 0xcafebabedeadbeefULL;
xstate2 = 0xfeedfacecafebabeULL;
rounds = 1;
}
// xorshift128+ PRNG 实现 (与 64 位代码匹配)
uint64_t xorshift128p() {
uint64_t answer = 0;
uint64_t t = 0;
uint64_t s = 0;
// 内部循环次数由 rounds 决定
for (int i = 0; i <= rounds; i++) {
t = xstate1;
s = xstate2;
xstate1 = s;
t ^= (t << 23); // 0x17
t ^= (t >> 17); // 0x11
t ^= s ^ (s >> 26); // 0x1a
xstate2 = t;
answer = t + s; // xorshift128+ 的 '+' 部分
}
rounds = t & 0xFF; // 更新下一次调用的 rounds
return answer;
}
// 逆转字节变换 (交换奇偶位)
uint8_t char_bit_twiddle_reverse(uint8_t c) {
// 与原函数操作相同,因为交换两次等于没交换
uint64_t temp = 0;
temp = ((uint64_t)c & 0b01010101) << 1;
temp |= ((uint64_t)c & 0b10101010) >> 1;
return (uint8_t)temp;
}
// CRC64 实现 (与 64 位代码匹配)
uint64_t crc64(uint8_t *s, size_t n) {
uint64_t crc = 0xFFFFFFFFFFFFFFFFULL;
uint64_t poly = 0xC96C5795D7870F42ULL; // ECMA-182 polynomial (reversed)
for(size_t i = 0; i < n; i++) {
crc ^= s[i];
for(size_t j = 0; j < 8; j++) {
if (crc & 1) {
crc = (crc >> 1) ^ poly;
} else {
crc >>= 1;
}
}
}
return ~crc; // 返回取反后的 CRC
}
// 生成洗牌的索引映射 (用于逆转洗牌)
int *gen_shuffle_indices(size_t len) {
int *idx = malloc(sizeof(int) * len);
// 初始化索引数组 idx = [0, 1, 2, ..., len-1]
for (int i = 0; i < len; i++) {
idx[i] = i;
}
// 模拟程序中的洗牌过程,但作用于索引数组
seed(); // 确保使用相同的种子和 PRNG 状态
for (size_t i = 0; i < len; i++) {
uint64_t replace_idx = xorshift128p() % len;
// 交换 idx[i] 和 idx[replace_idx]
int temp = idx[replace_idx];
idx[replace_idx] = idx[i];
idx[i] = temp;
}
// idx[i] 现在表示原始位置 i 的字节被移动到了哪个新位置
// 我们需要逆映射:知道新位置 j 的字节来自哪个原始位置 k
int *reverse_idx = malloc(sizeof(int) * len);
for (int i = 0; i < len; i++) {
reverse_idx[idx[i]] = i;
}
free(idx);
return reverse_idx; // reverse_idx[j] = k
}
gen_shuffle_indices 的目的是找到洗牌的顺序并生成一个逆映射,以便我们可以撤销洗牌操作。我将这些辅助函数链接在一起以找到 flag:
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#include <string.h>
// ... (包含上面定义的 seed, xorshift128p, char_bit_twiddle_reverse, crc64, gen_shuffle_indices 函数) ...
int main() {
// 从反汇编或调试器中提取的预期 CRC32 值 (注意:程序比较的是 CRC64 的低 32 位)
uint32_t expected_crcs[0x20] = {
0xb62a1500, 0x1d5c0861, 0x4c6f6e28, 0x4312c5af, 0x3cd56ab6, 0x1e6ab55b,
0x3cd56ab6, 0xc06c89bf, 0xed3f1f80, 0xbaf0e1e8, 0xbfab26a6, 0x3cd56ab6,
0xb3e0301b, 0xbaf0e1e8, 0xe1e5eb68, 0xb0476f74, 0xb3e0301b, 0x3cd56ab6,
0xbfab26a6, 0xe864d8ce, 0x4c6f6e28, 0x4312c5af, 0xb3e0301b, 0x9d14f94b,
0xee9840ef, 0x3cd56ab6, 0xbfab26a6, 0xbfab26a6, 0x9d14f94b, 0xbaf0e1e8,
0x14dd3bc7, 0x97329582
};
uint8_t shuffled_then_transformed_bytes[0x20] = {0}; // 存储逆推 CRC 得到的字节
uint8_t shuffled_bytes[0x20] = {0}; // 存储逆转变换后的字节
uint8_t original_bytes[0x21] = {0}; // 最终的 flag 缓冲区
// 步骤 1: 对每个期望的 CRC 值,暴力破解出对应的原始字节 (洗牌后、变换前的字节)
for (int i = 0; i < 0x20; i++) {
uint8_t found_byte = 0;
for (uint16_t c = 0; c <= 255; c++) {
uint8_t current_byte = (uint8_t)c;
// 计算该字节的 CRC64,取低 32 位
uint32_t computed_crc = (uint32_t)(crc64(¤t_byte, 1) & 0xFFFFFFFF);
if (computed_crc == expected_crcs[i]) {
found_byte = current_byte;
break; // 找到匹配字节
}
}
if (found_byte == 0 && expected_crcs[i] != (uint32_t)(crc64(&found_byte, 1) & 0xFFFFFFFF)) {
printf("Warning: Could not find byte for CRC 0x%x at index %d\n", expected_crcs[i], i);
}
shuffled_then_transformed_bytes[i] = found_byte;
}
// 步骤 2: 逆转字节变换 (交换奇偶位)
for (int i = 0; i < 0x20; i++) {
shuffled_bytes[i] = char_bit_twiddle_reverse(shuffled_then_transformed_bytes[i]);
}
// 步骤 3: 获取洗牌的逆序索引
int *reverse_shuffle_idx = gen_shuffle_indices(0x20);
// 步骤 4: 根据逆序索引,将字节放回原始位置
for (int i = 0; i < 0x20; i++) {
original_bytes[reverse_shuffle_idx[i]] = shuffled_bytes[i];
}
free(reverse_shuffle_idx);
// 步骤 5: 打印结果
printf("Flag: %s\n", original_bytes); // original_bytes 已经是 null 结尾的字符串
return 0;
}
/* 编译运行:
gcc solve.c -o solve -lm (如果用了 math.h, 虽然这里没用)
./solve
输出应为: Flag: HTB{h34v3n5_g4t3_0p3n5_b0th_w4y5}
*/
最终得到的 Flag 是 HTB{h34v3n5_g4t3_0p3n5_b0th_w4y5}。
 微信
微信